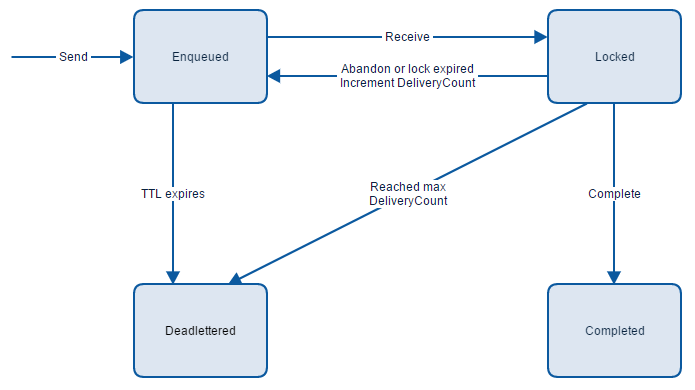
Around the beginning of April 2020 Udi Dahan, owner of Particular Software, released his course in a form of online videos, for free. The big deal is that Udi is one of the world’s foremost experts on Service-Oriented Architecture, Distributed Systems, and Domain-Driven Design. This was a trigger for me and my whole team to watch the course and have a weekly discussion session to talk through completed chapters. Here is what I learned.
Use messaging
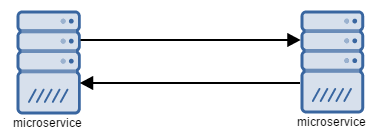
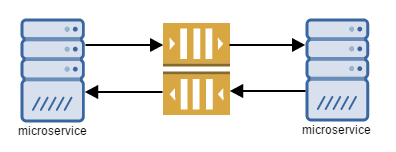
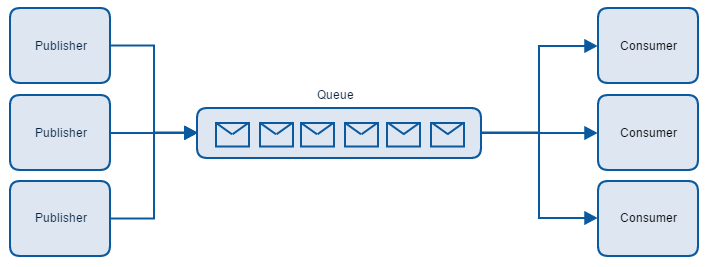
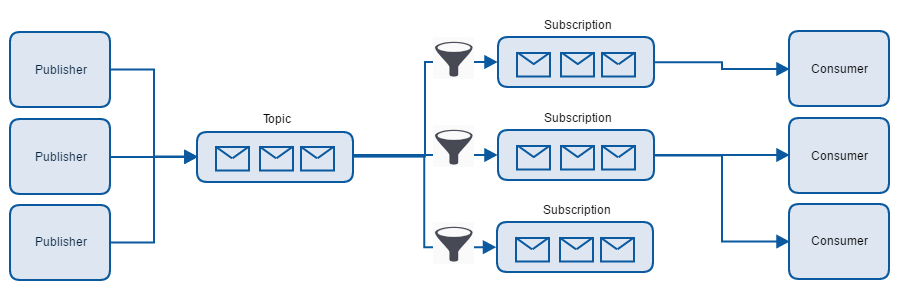
In his course, Udi highlighted many times, that messaging can solve most of your service-to-service communication. It may be slower than traditional RPC calls, but it’s more reliable and stable. It also scales better, because it doesn’t really matter how many subscribers there are, but rather how easy we can change the existing architecture.
With RPCs, services are strongly bonded together and need to support the same contract. When the change is needed, we often need to change more than one service. With messaging we can use messages that are already sent and build a service that we need.
It is also worth mentioning that messaging systems are in the business for a long time and there is a handful of solutions to choose from. It’s not a technology that is still changing quickly, but it’s been here for a while.
There’s no single best solution
This is something that was repeated dozens of times across the course. Udi showed the best available approaches and architectural styles available: RPCs, messaging, micro-services, CQRS, Sagas, and showed their good and bad usages. All those concepts are great, but it doesn’t mean that we should use one of them for everything. It’s actually better to combine a few approaches, technologies, database models and use whatever suits the problem best.
For example, if CQRS works great for one e-commerce solution, it doesn’t mean that now it is the formula for every e-commerce there is. Therefore we shouldn’t take unconsciously whatever worked for previous project without greater analysis.
Find your service boundaries
This was one of the most important chapters and an a-ha moment for me and my teammates. Udi explained how important it is to find the service boundaries – places where a business domain can be divided into smaller pieces. It also defines the best places where big codebase can be divided into smaller, independent services.
Let’s take a look at the example. Let’s say we are building a hospitality system, that a guest can interact with.
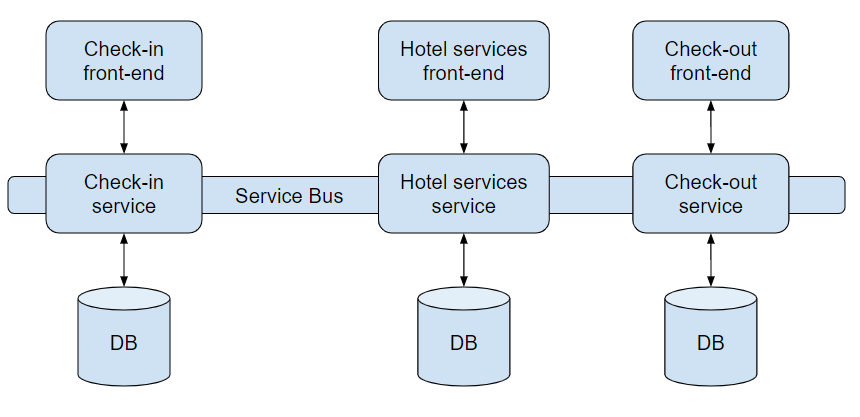
So we have nicely separated micro-services, each with separate front-end and DB. They are communicating via messages in Service Bus and save data they need in DB, in the form they need them. Every change done by the user is saved in DB and propagated via message.
So what’s wrong?
It may seem that it’s a perfect decoupled solution, that can be scaled according to needs. However, there are a few problems. The first one is that we have a lot on infrastructure to maintain: services and databases must have a deployment process and with this approach, we are going to have more and more small services.
The second one is scalability. They seem easy to scale because everything is separate, but in most cases, there will be no need to do so. We will end up using resources we do not need. The other thing is that it’s not easy to maintain many instances of a service, where you have the same database. Stateful services are hard to scale, where stateless services can be scaled easily. Scalable services need to be designed with this specific goal in mind.
The third and less obvious one is that those services are actually not decoupled. They are working on the same data: user basic data, reservation details, reservation suborders, and payments. We will end up having all those data in every database. Don’t get me wrong, data duplication isn’t a bad thing when it comes to reading. But when a change is necessary, it has to be synchronized with every service that uses this data. Now, let’s have a look at a different approach.
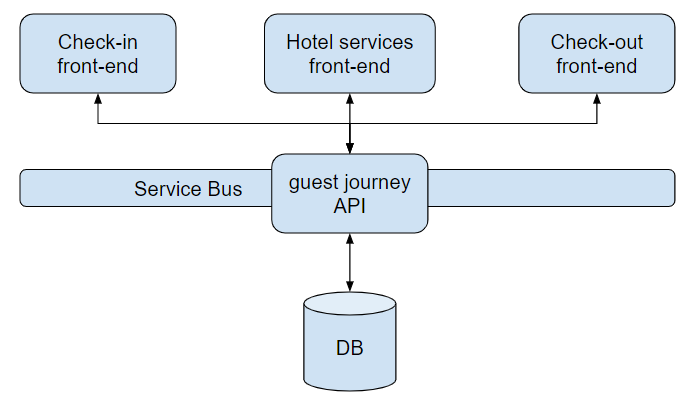
In this approach, we still have separate front-ends but we have a single API and DB. The deployment process is easier, applying a change of contract is also easier, because we can do it all at once and we need much less synchronization. Of course, this is only an example and it wouldn’t fit every scenario, but here it makes sense.
Micro-services approach doesn’t have to be better than the monolith
When looking at an example above, we clearly see that having slightly bigger services can bring certain advantages to our architecture. When building micro-service it is a common pattern, that it should do one thing only. It can lead to services, that would have a single method in their APIs. While it may make sense in some cases, it would result in creating many very small services, that contain more synchronization code, than the actual business logic.
On the other hand, a monolith does not need to be a bad idea. If we can make it performant enough and the codebase isn’t that bad, then it actually has some advantages. For example, introducing a change is far easier and quicker than in many micro-services. Also, we have all business logic and contracts in front of our eyes, where we can easily see it. It’s also easier to write unit tests in the monolith than integration tests with a micro-service approach.
Don’t try to model reality – it doesn’t exist
A very powerful sentence, that Udi said when talking about domain modeling. Although it is said that Object-Oriented Programming should mimic the real world, it doesn’t seem to be the right approach. Let me bring the example that Udi mentioned.
We need to count the amount for transactions that were done this week and the last week. When reflecting that as a real-life model, we would end up having a table of transactions with dates and amounts. Like this:
![]()
Then when we need the sum, we would calculate it on the fly. This, of course, would work, but calculating the sum of transactions every time is just a bad idea. If we shift our thinking, we could just have a structure like this:
![]()
It doesn’t remind a transaction list from the real-world, but in this case, we simply don’t need it. It will require some maintenance when the week is over, but it will be far less than calculating the sum on every read.
The summary
Learn Advanced Distributed Systems Design course changed the way I’m thinking about distributed architecture and micro-services. Udi is an amazing speaker, that used his experience from many real-life projects and was able to explain the most complicated concepts in a way that child would understand.
Although it wasn’t easy to go through 30+ hours of the course, it was a huge dose of knowledge and I would recommend it to anyone.
BTW, here is the link: https://particular.net/adsd







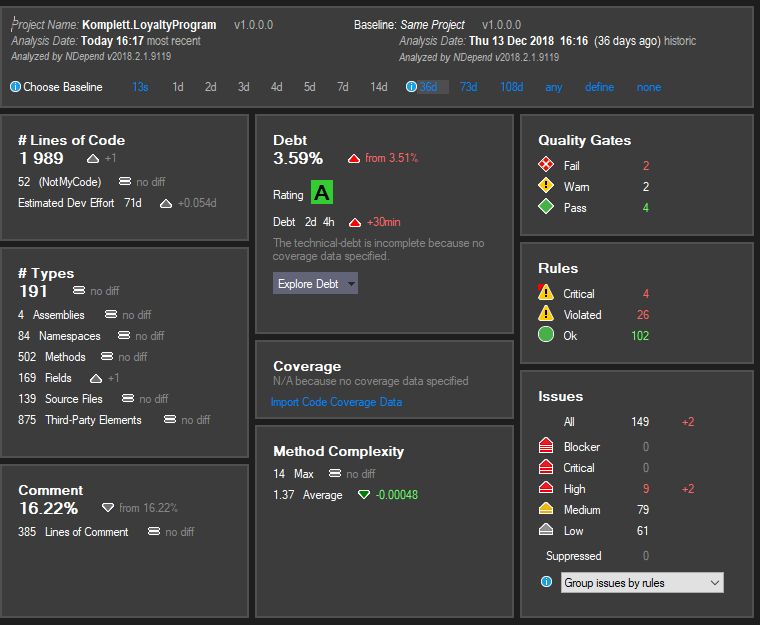
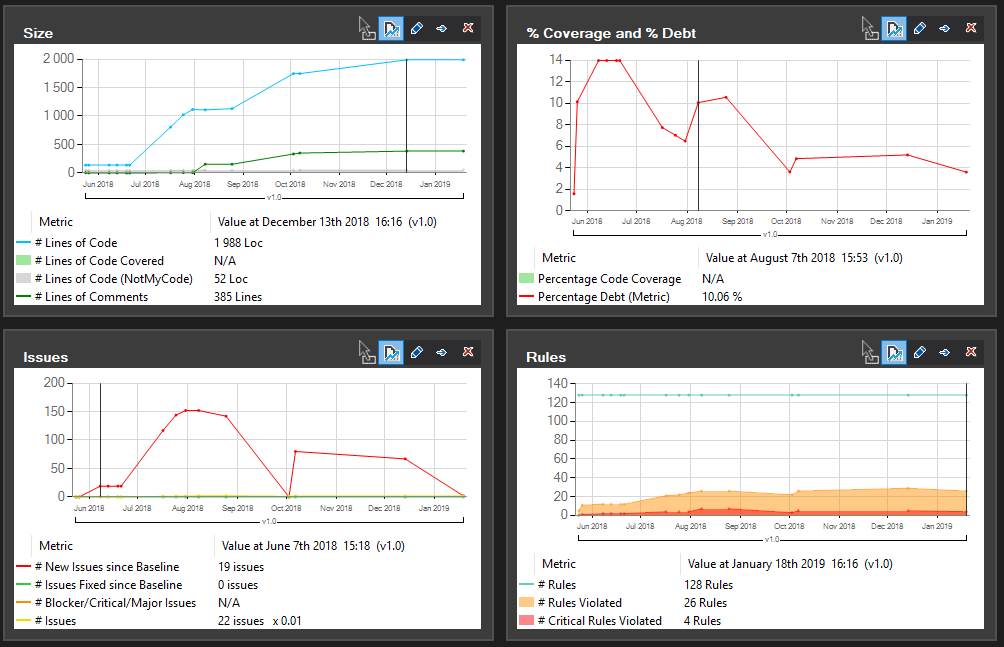

 I need to admit, that I got an NDepend license for free to test it out. If it wasn’t for Patrick Smacchia from NDepend, I wouldn’t discover that anytime soon. And I would never learn, that no matter how good you get in your work, you always can do better.
I need to admit, that I got an NDepend license for free to test it out. If it wasn’t for Patrick Smacchia from NDepend, I wouldn’t discover that anytime soon. And I would never learn, that no matter how good you get in your work, you always can do better.

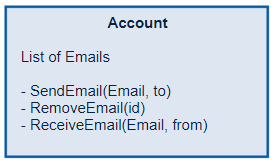

 Actor model is best suited for data that is well grained, so that actors can be easily identified and their state can be easily decoupled. Accessing data by an actor is instant, because it holds it in memory and the same goes to notifying other actors. Taking that into account, Microsoft Orleans will be most beneficial where application needs to handle many small operations that changes application state. In a traditional storage, in example SQL database, application needs to handle concurrency when accessing the data, where in Orleans data are well divided. You may think that there have to be data updates that changes shared storage, but that’s a matter of changing the way the architecture is planned.
Actor model is best suited for data that is well grained, so that actors can be easily identified and their state can be easily decoupled. Accessing data by an actor is instant, because it holds it in memory and the same goes to notifying other actors. Taking that into account, Microsoft Orleans will be most beneficial where application needs to handle many small operations that changes application state. In a traditional storage, in example SQL database, application needs to handle concurrency when accessing the data, where in Orleans data are well divided. You may think that there have to be data updates that changes shared storage, but that’s a matter of changing the way the architecture is planned.