
Entity Framework Core 5 is a great ORM to use and connect to the database with. It is easy to use and easy to understand. It offers just enough for the most common scenarios. So what about inserting big amounts of data in a one go? Would it be fast enough?
Let’s have a look at the code
As my example, I’ll take a very simple entity – a Profile and PrimeHotel repository available here at my GitHub.
My DbContext is very simple and it looks like this:
public class PrimeDbContext : DbContext
{
public PrimeDbContext(DbContextOptions<PrimeDbContext> options)
: base(options)
{
}
public virtual DbSet<Room> Rooms { get; set; }
public virtual DbSet<Profile> Profiles { get; set; }
public virtual DbSet<Reservation> Reservations { get; set; }
}
And Profile entity looks like this:
public class Profile
{
public int Id { get; set; }
public string Ref { get; set; }
public string Forename { get; set; }
public string Surname { get; set; }
public string TelNo { get; set; }
public string Email { get; set; }
public DateTime? DateOfBirth { get; set; }
}
Because I’ll be using WebApi for the ease of demonstration, I’ll create a ProfileController.
[ApiController]
[Route("[controller]")]
public class ProfileController : ControllerBase
{
private readonly PrimeDbContext primeDbContext;
private readonly string connectionString;
public ProfileController(PrimeDbContext _primeDbContext, IConfiguration _configuration)
{
connectionString = _configuration.GetConnectionString("HotelDB");
primeDbContext = _primeDbContext;
}
}
For now, it’s pretty empty, but now you get the base that we will start with.
Let’s get profiles… lots of them!
To test an insert of many entities at once we need to generate a lot of testing data. I like to have my test data as close to real values as possible, so to get those, I’ll use a Bogus nugget package.
Bogus is robust and very easy to use fake data generator. It will generate random values, that will fit a given context, like a surname, age, address, e-mail, company name, and so on. There are dozens of options. Go see for yourself in its documentation.
Generating any number of profiles will look like this:
private IEnumerable<Profile> GenerateProfiles(int count)
{
var profileGenerator = new Faker<Profile>()
.RuleFor(p => p.Ref, v => v.Person.UserName)
.RuleFor(p => p.Forename, v => v.Person.FirstName)
.RuleFor(p => p.Surname, v => v.Person.LastName)
.RuleFor(p => p.Email, v => v.Person.Email)
.RuleFor(p => p.TelNo, v => v.Person.Phone)
.RuleFor(p => p.DateOfBirth, v => v.Person.DateOfBirth);
return profileGenerator.Generate(count);
}
Inserting profiles with Entity Framework Core 5
I don’t want to send all those profiles in a request, because that would be a huge amount of data. Transferring that to a controller and deserialization on the ASP.NET Core 5 side can take a while, and it’s not really the part I want to test. This is why I choose to generate my profiles in the controller method and insert it right after that.
The code for the whole thing is really straightforward:
[HttpPost("GenerateAndInsert")]
public async Task<IActionResult> GenerateAndInsert([FromBody] int count = 1000)
{
Stopwatch s = new Stopwatch();
s.Start();
var profiles = GenerateProfiles(count);
var gererationTime = s.Elapsed.ToString();
s.Restart();
primeDbContext.Profiles.AddRange(profiles);
var insertedCount = await primeDbContext.SaveChangesAsync();
return Ok(new {
inserted = insertedCount,
generationTime = gererationTime,
insertTime = s.Elapsed.ToString()
});
}
Additionally, I added a Stopwatch to measure how long does it take to generate profiles as well as insert them. In the end, I’m returning an anonymous type to easily return more than one result at a time.
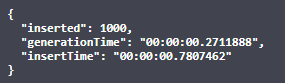
Finally, let’s test it out. For 1000 profiles I got:
But wait, let’s try something bigger, like 100000 entities:
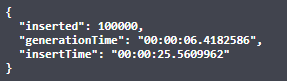
25 seconds? Really? Not that impressive.
What it does underneath? Let’s check with SQL Server Profiler:
exec sp_executesql N'SET NOCOUNT ON; DECLARE @inserted0 TABLE ([Id] int, [_Position] [int]); MERGE [Profiles] USING ( VALUES (@p0, @p1, @p2, @p3, @p4, @p5, @p6, 0), (@p7, @p8, @p9, @p10, @p11, @p12, @p13, 1), (@p14, @p15, @p16, @p17, @p18, @p19, @p20, 2), (@p21, @p22, @p23, @p24, @p25, @p26, @p27, 3), ... ) AS i ([DateOfBirth], [Email], [Forename], [Ref], [ReservationId], [Surname], [TelNo], _Position) ON 1=0 WHEN NOT MATCHED THEN INSERT ([DateOfBirth], [Email], [Forename], [Ref], [ReservationId], [Surname], [TelNo]) VALUES (i.[DateOfBirth], i.[Email], i.[Forename], i.[Ref], i.[ReservationId], i.[Surname], i.[TelNo]) OUTPUT INSERTED.[Id], i._Position INTO @inserted0; SELECT [t].[Id] FROM [Profiles] t INNER JOIN @inserted0 i ON ([t].[Id] = [i].[Id]) ORDER BY [i].[_Position]; ',N'@p0 datetime2(7), @p1 nvarchar(4000), @p2 nvarchar(4000), @p3 nvarchar(4000), @p4 int, @p5 nvarchar(4000), ... @p0='1995-02-22 09:40:44.0952799', @p1=N'Sherri_Orn@gmail.com', @p2=N'Sherri', ...
SqlBulkCopy to the rescue
SqlBulkCopy is a class that was introduced a while ago, specifically in .Net Framework 2.0 – 18 years ago! SqlBulkCopy will only work to save data in a SQL Server database, but its source can be anything, as long as it’s results can be loaded to DataTable or read by IDataReader.
Let’s have a look at how we can use it in our example.
[HttpPost("GenerateAndInsertWithSqlCopy")]
public async Task<IActionResult> GenerateAndInsertWithSqlCopy([FromBody] int count = 1000)
{
Stopwatch s = new Stopwatch();
s.Start();
var profiles = GenerateProfiles(count);
var gererationTime = s.Elapsed.ToString();
s.Restart();
var dt = new DataTable();
dt.Columns.Add("Id");
dt.Columns.Add("Ref");
dt.Columns.Add("Forename");
dt.Columns.Add("Surname");
dt.Columns.Add("Email");
dt.Columns.Add("TelNo");
dt.Columns.Add("DateOfBirth");
foreach (var profile in profiles)
{
dt.Rows.Add(string.Empty, profile.Ref, profile.Forename, profile.Surname, profile.Email, profile.TelNo, profile.DateOfBirth);
}
using var sqlBulk = new SqlBulkCopy(connectionString);
sqlBulk.DestinationTableName = "Profiles";
await sqlBulk.WriteToServerAsync(dt);
return Ok(new
{
inserted = dt.Rows.Count,
generationTime = gererationTime,
insertTime = s.Elapsed.ToString()
});
}
First, we need to define a DataTable. It needs to represent the Profiles table because this is our destination table that we are going to use.
Then with WriteToServerAsync we are loading profiles to the database. Let’s have a look at how does it looks like in SQL.
select @@trancount; SET FMTONLY ON select * from [Profiles] SET FMTONLY OFF exec ..sp_tablecollations_100 N'.[Profiles]' insert bulk [Profiles] ( [Ref] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS, [Forename] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS, [Surname] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS, [TelNo] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS, [Email] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS, [DateOfBirth] DateTime2(7))
How does it work internally? StackOverflow comes with an answer:
SqlBulkCopy does not create a data file. It streams the data table directly from the .Net DataTable object to the server using the available communication protocol (Named Pipes, TCP/IP, etc…) and insert the data to the destination table in bulk using the same technique used by BCP.
Two totally different approaches. What about the performance? Let’s compare those two.
The performance
The outcome of a performance check is not a huge surprise. SqlBulkCopy is meant to insert data fast and it is extremely performant.
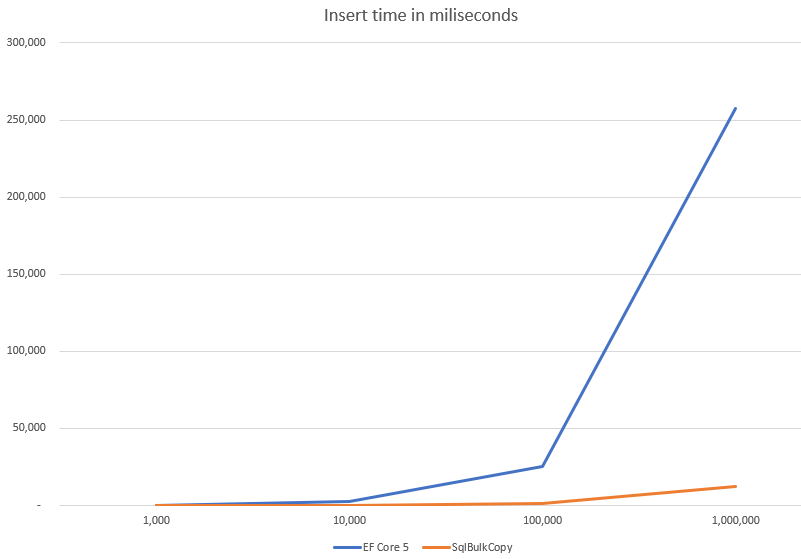
Big differences start to show when you insert more than 10 thousand entities at a time. Over that number, it might be wort to reimplement your code to use SqlBulkCopy instead of Entity Framework Core 5.
What about other operations?
When it comes to handling big amounts of data things are starting to be a little more tricky. You might want to take a look at the database improvements and what data you actually need to operate on. Have in mind that operations on big chunks of data are much faster when done on the database side.
I had a case once where I needed to perform and update on around a million entities, once a day. I combined a few things and it worked out pretty good.
- create a temporary table, i.e. T1
- insert data with SqlBulkCopy
- perform an update on the database side
- select any data you might need, i.e. for logging
- delete a temporary table
I know this is moving business logic inside the database, but some sacrifices are required if this update operation needs to be fast.
All code posted here is available on my GitHub.
Cheers!
with BulkInsert you can also configure the batch size (number of rows) before commit (so has relevance for tranlog size etc), so would be interesting to see what/any impact tweaking that param in your test timings.
I’ve found that SaveChangesASync() is dramatically slower than SaveChanges() non-async, especially for inserting or saving large amounts of data. Its to the point where my implementation is ~ var saveResults = await Task.Run(() => Context.SaveChanges()).ConfigureAwait(false);
Gregory. I just tested and in my case there is no visible difference between SaveChanges() and SaveChangesAsync().
In your case it might be a matter of handling concurrency. Task.Run creates new thread and ConfigureAwait(false) enforce synchronization with that thread ant the end. This might be the cause of such difference.
In general we should avoid using Task.Run wherever we can, but have a read about it from Stephen Cleary (https://blog.stephencleary.com/)
No, in my testing it was done before Task.Run was introduced. There must be something else at play, as I was able to recreate it in a sample app. Whenever I have time, I’ll go back and have a deeper look.
Thanks, I appreciate it 🙂
– You should change `options.UseSqlServer` to `options.UseSqlServer(options => options.MaxBatchSize(100000))` if you want fewer round trips to the database.
– Also you should consider that `SaveChanges()` does change tracking and validation.
You can check the power of SqlBulkCopy in: https://www.inforcustom.duckdns.org/en-us/Documentacion/insertbulkbestia/ibbintroduccion