![]() Recently I’m diving into Microsoft actor model implementation – Service Fabric Reliable Actors. Apart from Microsoft Orleans, is another one worth looking into. Let’s start from the beginning.
Recently I’m diving into Microsoft actor model implementation – Service Fabric Reliable Actors. Apart from Microsoft Orleans, is another one worth looking into. Let’s start from the beginning.
What is Service Fabric? It is many things and can be compared to Kubernetes:
- Simplify microservices development and application lifecycle management
- Reliably scale and orchestrate containers and microservices
- Data-aware platform for low-latency, high-throughput workloads with stateful containers or microservices
- Run anything – your choice of languages and programming models
- Run anywhere – supports Windows/Linux in Azure, on-premises, or other clouds
- Scales up to thousands of machines
Source: https://azure.microsoft.com/en-us/services/service-fabric/
From my perspective, it is just another way to manage micro-services. It can be set up on Azure or on-premise. Its biggest disadvantage is it’s dashboard, that does not offer much, comparing to IIS or Azure.
What are Reliable Actors? It is a Service Fabric implementation of an actor pattern, that is great for handling many small parallel operations. Actor, in this case, is a small piece of business logic, that can hold state and all actors can work simultaneously and independently, no matter if there is a hundred or hundred thousand of them.
If you’re new to actor model, you can have a look at an introduction to Microsoft Orleans. It covers all the basics: Getting started with Microsoft Orleans
Scenario
Let’s have an example to understand how all of this can be used in practice.
Let’s build price comparer micro-service, that will maintain sellers, products and offers for products. Every seller can have many offers for many products and every product will have many offers from many sellers. Something that in DB will look like this:
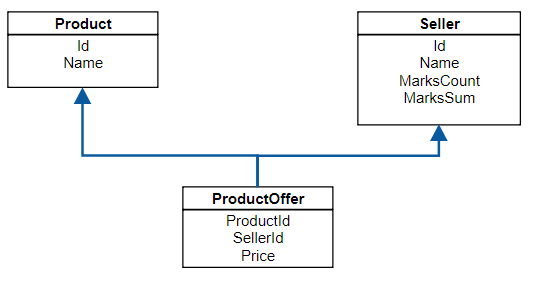
The main features of this service are:
- it is a REST micro-service, so all communication will go through it’s API
- it needs to persist its state
- when getting a product, it needs to respond with json, where offers are sorted by seller rating descending
The last requirement forces us to update product offers whenever seller rating changes. Whenever seller rating changes, all its product offers need to be reordered. It sounds complicated, but it’s easier than it seems. API looks like this:
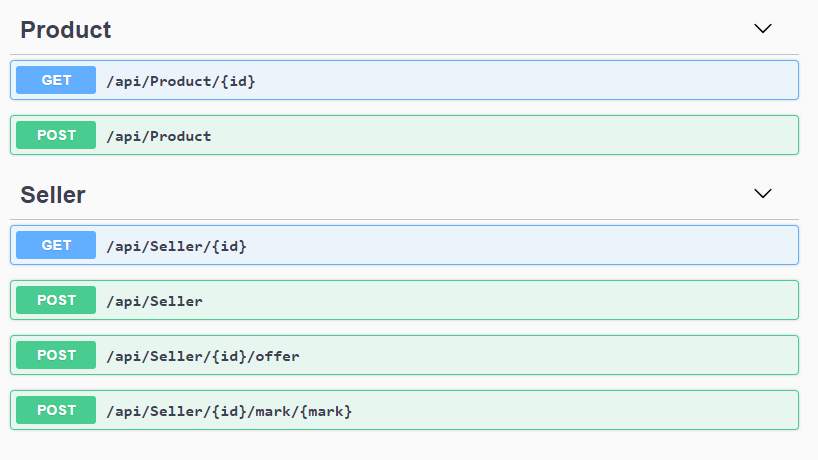
And Json that we would like to get in return, looks like this:

Simple micro-service approach
I already showed you how DB model can look like and this is precisely the way I’m going to implement it. Every operation will go to DB and take data from there. The architecture will be simple:
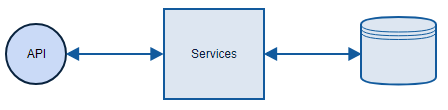
Of course I might keep my state in memory and update it whenever something changes, but this is rather difficult. In fact, cache invalidation is told to be one of the two hardest problems in software development. Right after naming things.
Let’s have a look how SellerController is built, it’s rather simple:
[Route("api/[controller]")]
[ApiController]
public class SellerController : ControllerBase
{
private readonly ISellerRepository _sellerRepository;
public SellerController(ISellerRepository sellerRepository)
{
_sellerRepository = sellerRepository;
}
[HttpGet("{id}")]
public async Task<ActionResult<string>> Get(string id)
{
try
{
var seller = await _sellerRepository.Get(id);
return new JsonResult(seller);
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
[HttpPost]
public async Task Post([FromBody] Seller seller)
{
try
{
await _sellerRepository.Save(seller);
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
[HttpPost("{id}/mark/{mark}")]
public async Task AddMark(string id, decimal mark)
{
try
{
var seller = await _sellerRepository.Get(id);
if (seller == null)
{
return;
}
seller.MarksCount += 1;
seller.MarksSum += mark;
await _sellerRepository.Update(seller);
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
}
All the work is done in SellerRepository:
public class SellerRepository : ISellerRepository
{
private const string RemoveSeller = @"DELETE FROM Seller WHERE Id = @Id";
private const string InsertSeller = @"INSERT INTO Seller (Id, Name, MarksCount, MarksSum) VALUES (@Id, @Name, @MarksCount, @MarksSum)";
private const string UpdateSellerRating = @"UPDATE Seller SET MarksCount = @MarksCount, MarksSum = @MarksSum WHERE Id = @Id";
private const string GetSeller = @"SELECT Id, Name, MarksCount, MarksSum FROM Seller WHERE Id = @id";
private const string GetSellerOffers = @"SELECT ProductId, Price FROM ProductOffer WHERE SellerId = @id";
private readonly IConfigurationRoot _configuration;
public SellerRepository(IConfigurationRoot configuration)
{
_configuration = configuration;
}
public async Task Save(Seller seller)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
await connection.ExecuteAsync(RemoveSeller, new { seller.Id });
await connection.ExecuteAsync(InsertSeller, seller);
}
}
public async Task<Seller> Get(string id)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
var sellerOffers = await connection.QueryAsync<Offer>(GetSellerOffers, new { id });
var seller = await connection.QuerySingleAsync<Seller>(GetSeller, new { id });
seller.Offers = sellerOffers.ToList();
return seller;
}
}
public async Task Update(Seller seller)
{
using (var connection = new SqlConnection(_configuration.GetConnectionString("DbConnectionString")))
{
await connection.ExecuteAsync(UpdateSellerRating, seller);
}
}
}
To be able to use code like this:
connection.QuerySingleAsync<Seller>(GetSeller, new { id })
I used Dapper nuget package – very handy tool that enriches simple IDbConnection with new features.
Service Fabric approach
The functionality of Service Fabric implementation will be exactly the same. Small micro-service that exposes REST API and ensures that state is persistent. And this is where similarities end. First, let’s have a look at the project structure:
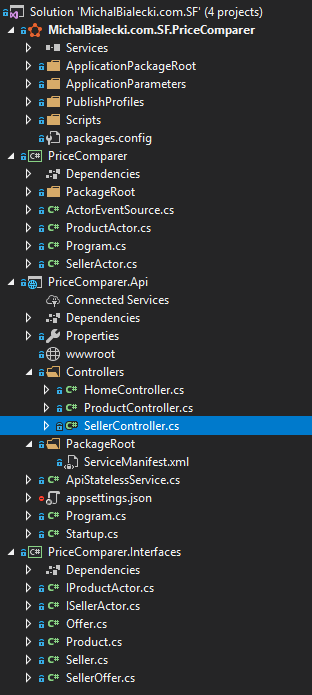
From the top:
- MichalBialecki.com.SF.PriceComparer – have you noticed Service Fabric icon? It contains configuration how to set up SF cluster and what application should be hosted. It also defines how they will be scaled
- PriceComparer – Business logic for API project, it contains actor implementation
- PriceComparer.Api – REST API that we expose. Notice that we also have ServiceManifest.xml that is a definition of our service in Service Fabric
- PriceComparer.Interfaces – the name speaks for itself, just interfaces and dtos
Controller implementation is almost the same as in the previous approach. Instead of using repository it uses actors.
[Route("api/[controller]")]
[ApiController]
public class SellerController : ControllerBase
{
[HttpGet("{id}")]
public async Task<ActionResult<string>> Get(string id)
{
try
{
var sellerActor = ActorProxy.Create<ISellerActor>(new ActorId(id));
var seller = await sellerActor.GetState(CancellationToken.None);
return new JsonResult(seller);
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
[HttpPost]
public async Task Post([FromBody] Seller seller)
{
try
{
var sellerActor = ActorProxy.Create<ISellerActor>(new ActorId(seller.Id));
await sellerActor.AddSeller(seller, CancellationToken.None);
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
[HttpPost("{id}/offer")]
public async Task AddOffer(string id, [FromBody] Offer offer)
{
try
{
var sellerActor = ActorProxy.Create<ISellerActor>(new ActorId(id));
await sellerActor.AddOffer(offer, CancellationToken.None);
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
[HttpPost("{id}/mark/{mark}")]
public async Task AddMark(string id, decimal mark)
{
try
{
var sellerActor = ActorProxy.Create<ISellerActor>(new ActorId(id));
await sellerActor.Mark(mark, CancellationToken.None);
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
}
ActorProxy.Create<ISellerActor> is the way we instantiate an actor, it is provided by the framework. Implementation of SellerActor needs to inherit Actor class. It also defines on top of the class how the state will be maintained. In our case it will be persisted, that means it will be saved as a file on a disk on the machine where the cluster is located.
[StatePersistence(StatePersistence.Persisted)]
internal class SellerActor : Actor, ISellerActor
{
private const string StateName = nameof(SellerActor);
public SellerActor(ActorService actorService, ActorId actorId)
: base(actorService, actorId)
{
}
public async Task AddSeller(Seller seller, CancellationToken cancellationToken)
{
await StateManager.AddOrUpdateStateAsync(StateName, seller, (key, value) => value, cancellationToken);
}
public async Task<Seller> GetState(CancellationToken cancellationToken)
{
return await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
}
public async Task AddOffer(Offer offer, CancellationToken cancellationToken)
{
var seller = await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
var existingOffer = seller.Offers.FirstOrDefault(o => o.ProductId == offer.ProductId);
if (existingOffer != null)
{
seller.Offers.Remove(existingOffer);
}
seller.Offers.Add(offer);
var sellerOffer = new SellerOffer
{
ProductId = offer.ProductId,
Price = offer.Price,
SellerId = seller.Id,
SellerRating = seller.Rating,
SellerName = seller.Name
};
var productActor = ActorProxy.Create<IProductActor>(new ActorId(offer.ProductId));
await productActor.UpdateSellerOffer(sellerOffer, cancellationToken);
await StateManager.SetStateAsync(StateName, seller, cancellationToken);
}
public async Task Mark(decimal value, CancellationToken cancellationToken)
{
var seller = await StateManager.GetOrAddStateAsync(StateName, new Seller(), cancellationToken);
seller.MarksCount += 1;
seller.MarksSum += value;
await StateManager.SetStateAsync(StateName, seller, cancellationToken);
foreach (var offer in seller.Offers)
{
var productActor = ActorProxy.Create<IProductActor>(new ActorId(offer.ProductId));
await productActor.UpdateSellerRating(seller.Id, seller.Rating, cancellationToken);
}
}
}
Notice that in order to use state, we use StateManager, also provided by the framework. The safest way is to either user GetOrAddStateAsync or SetStateAsync. Fun fact – all methods are asynchronous, there are no sync ones. There is a good emphasis on making code async, so that it can be run better in parallel with other jobs.
Take a look at Mark method. In order to mark a seller, we need to get its state, increment counters and save state. Then we need to update all product offers that seller has. Let’s take a look at how updating product looks like:
public async Task UpdateSellerRating(string sellerId, decimal sellerRating, CancellationToken cancellationToken)
{
var product = await StateManager.GetOrAddStateAsync(StateName, new Product(), cancellationToken);
var existingMatchingOffer = product.Offers.FirstOrDefault(o => o.SellerId == sellerId);
if (existingMatchingOffer != null)
{
existingMatchingOffer.SellerRating = sellerRating;
product.Offers = product.Offers.OrderByDescending(o => o.SellerRating).ToList();
await StateManager.SetStateAsync(StateName, product, cancellationToken);
}
}
We are updating seller rating in his offer inside a product. That can happen for thousands of products, but since this job is done in different actors, it can be done in parallel. Architecture for this approach is way different when compared to simple micro-service.
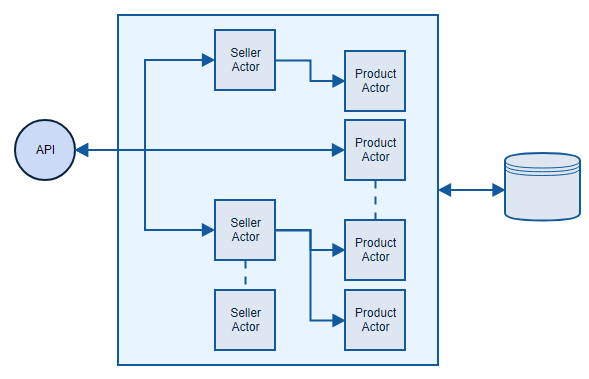
Comparison
To compare both approaches I assumed I need a lot of data, so I prepared:
- 1000 sellers having
- 10000 products with
- 100000 offers combined
It sounds a lot, but in a real-life price comparer, this could be just a start. A good starting point for my test, though. The first thing that hit me was loading this data into both services. Since both approaches exposed the same API, I just needed to make 11000 requests to initialize everything. With Service Fabric it all went well, after around 1 minute everything was initialized. However with simple DB approach… it throws SQL timeout exceptions. It turned out, that it couldn’t handle so many requests, even when I extended DB connection timeout. I needed to implement batch init, and after a few tries, I did it. However, the time that I needed to initialize all the data wasn’t so optimistic.
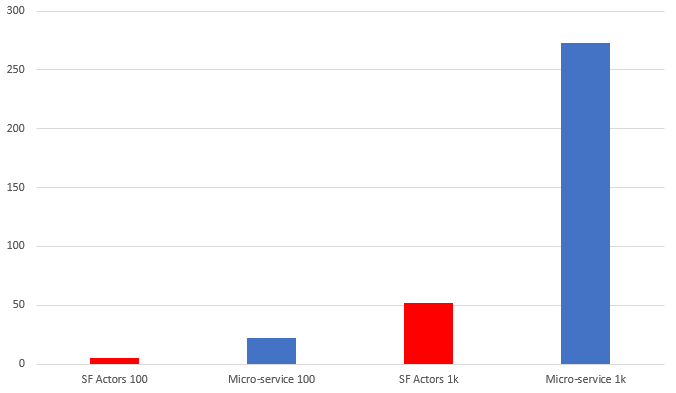
First two columns stand for initializing everything divided by 10, and second two stands for full initialization. Notice that a simple DB approach took around 5 times more than Service Fabric implementation!
![]() To test the performance of my services I needed to send a lot of requests at the same time. In order to do that I used Locust – a performance load tool. It can be easily installed and set up. After preparing a small file that represents a testing scenario, I just run it from the terminal and then I can go to its dashboard, that is accessible via a browser.
To test the performance of my services I needed to send a lot of requests at the same time. In order to do that I used Locust – a performance load tool. It can be easily installed and set up. After preparing a small file that represents a testing scenario, I just run it from the terminal and then I can go to its dashboard, that is accessible via a browser.
Let’s have a look at how the performance of the first approach looks like. In this case, Locust will simulate 200 users, that grows from 0 to 200, 20 users per second. It will handle around 30 requests per second with an average response time 40 ms. When I update that value to 400 users, it will handle around 50 requests per minute, but response time will go to around 3 seconds. That, of course, is not acceptable in micro-service development.
The second video shows the same test, but hitting Service Fabric app. This time I’d like to go bold and start off with 1000 users. It will handle around 140 RPM with an average response time around 30ms, which is even faster than 400 users and first approach. Then I’ll try 2000 users, have a look:
Summary
I showed you two approaches, both written in .Net Core 2.0. The first one is a very simple one using SQL DB, and the second one is Service Fabric with Reliable Actors. From my tests, I could easily see that actors approach is way more performant. Probably around 5 times in this specific case. Let’s point this out:
Pros:
- very fast in scenarios, where there are many small pieces of business logic, tightly connected to data
- trivial to try and implement – there is a Visual Studio project for that
Cons:
- It’s more complicated to implement than the regular approach
- Configuring Service Fabric with XML files can be frustrating
- Since everything handled by the framework, a developer has a bit less control over what’s happening
All in all, in my opinion, it’s worth trying.
![]() All code posted here you can find on my GitHub:
All code posted here you can find on my GitHub:
- Micro-service with SQL approach: https://github.com/mikuam/Blog
- Service Fabric Reliable Actors approach: https://github.com/mikuam/service-fabric-reliable-actors-example
“Microsoft’s approach to build something like Kubernetes” – check history better 😉
Microsoft started to create concept sf already in 2001, the sf itself was used from the very beginning of azure. It drives a dozen of very large azure services such as core azure apis, databases as-service, cosmos db, iot hub, skype for buissnes and more.
unlike kubernetes, sf can handle a statefulset. It also has a built-in database with reliable collections.
Good catch, I’ll fix it, thanks!
Pingback: dotnetomaniak.pl
You mentioned SF store the data in a file? Can it handle large sets of data? Will the db version be faster if you try this with large data?
If you are using actors for large data entities, you are defeating the purpose, or the aggregated root is not correctly selected.
A solution for that is to use the actor and its as a gateway/definition on how to find and find the large data on in the dedicted storage.